Spinning soccer ball

I have no interest whatever in the football, but here's a spinning truncated icosahedron (delete the *REFRESH commands to run in ARM BASIC):

10 REM Spinning soccer ball 20 REM!Keep p, q, r, s, t 30 MODE 9 : OFF 40 ORIGIN 640,512 : COLOUR 130 50 DIM xyz(59,2), tmp(59,2), b(2,2), c(2,2) 60 s = SQR5 + 1 : p = s/2 : q = p+2 : r = s+1 : t = p*3 70 FOR I% = 0 TO 59 80 READ xyz(I%,0), xyz(I%,1), xyz(I%,2) 90 NEXT 100 *REFRESH OFF 110 b = 0.5 : c = 0 120 b() = COS(b), 0, SIN(b), 0, 1, 0, -SIN(b), 0, COS(b) 130 REPEAT 140 c() = COS(c), -SIN(c), 0, SIN(c), COS(c), 0, 0, 0, 1 150 c() = c() . b() : tmp() = xyz() . c() 160 CLS 170 GCOL 3 : CIRCLE FILL 0, 0, 432 : GCOL 0 180 I% = 0 190 FOR J% = 0 TO 11 200 z = 0 210 FOR K% = I% TO I% + 4 220 z += tmp(K%,1) 230 NEXT 240 FOR K% = 0 TO 4 250 X% = 3200 * tmp(I%,0) / (36 + tmp(I%,1)) 260 Y% = 3200 * tmp(I%,2) / (36 + tmp(I%,1)) 270 IF K%<2 MOVE X%,Y% ELSE IF z<-2.5 PLOT 85,X%,Y% 280 I% += 1 290 NEXT 300 NEXT J% 310 WAIT : *REFRESH 320 c += 0.03 330 UNTIL FALSE 340 END 350 360 DATA 0, 1, t, -p, 2, r, p, 2, r, -1, q, s, 1, q, s 370 DATA 0, 1, -t, -p, 2, -r, p, 2, -r, -1, q, -s, 1, q, -s 380 DATA 0, -1, t, -p, -2, r, p, -2, r, -1, -q, s, 1, -q, s 390 DATA 0, -1, -t, -p, -2, -r, p, -2, -r, -1, -q, -s, 1, -q, -s 400 DATA 1, t, 0, 2, r, -p, 2, r, p, q, s, -1, q, s, 1 410 DATA 1, -t, 0, 2, -r, -p, 2, -r, p, q, -s, -1, q, -s, 1 420 DATA -1, t, 0, -2, r, -p, -2, r, p, -q, s, -1, -q, s, 1 430 DATA -1, -t, 0, -2, -r, -p, -2, -r, p, -q, -s, -1, -q, -s, 1 440 DATA t, 0, 1, r, -p, 2, r, p, 2, s, -1, q, s, 1, q 450 DATA t, 0, -1, r, -p, -2, r, p, -2, s, -1, -q, s, 1, -q 460 DATA -t, 0, 1, -r, -p, 2, -r, p, 2, -s, -1, q, -s, 1, q 470 DATA -t, 0, -1, -r, -p, -2, -r, p, -2, -s, -1, -q, -s, 1, -q
0
Comments
-
Nice one!
Add this one line to make it run in ARM BASIC on RISC OS with no further alterations:25 IF (INKEY(-256) AND &F0) = &A0 THEN *Set Alias$Refresh ||
In RISC OS, a | is a comment, and also(!) an escape character, so this sets an alias of "Refresh" to | effectively making it a no-op instead of an error.0 -
Very nice! I think my second non-trivial program in BBC Basic, certainly an early one, was a wireframe dodecahedron. On a BBC Micro of course, frame rate perhaps below 1fps, but not by too much.0
-
On an emulated Master 128 with Z80 Second Processor it was running at about 3 seconds per frame (⅓ FPS) but I don't know how much of that is calculation and how much rendering. I did it as much as anything as a test of my version 5 interpreter.On a BBC Micro of course, frame rate perhaps below 1fps, but not by too much.
0 -
The breakdown seems to be approximately as follows:Hated_moron wrote: »I don't know how much of that is calculation and how much rendering.- Rotation calculations: 1 second
- CLS: 0.1 seconds
- CIRCLE FILL: 0.4 seconds
- Drawing pentagons: 1.5 seconds
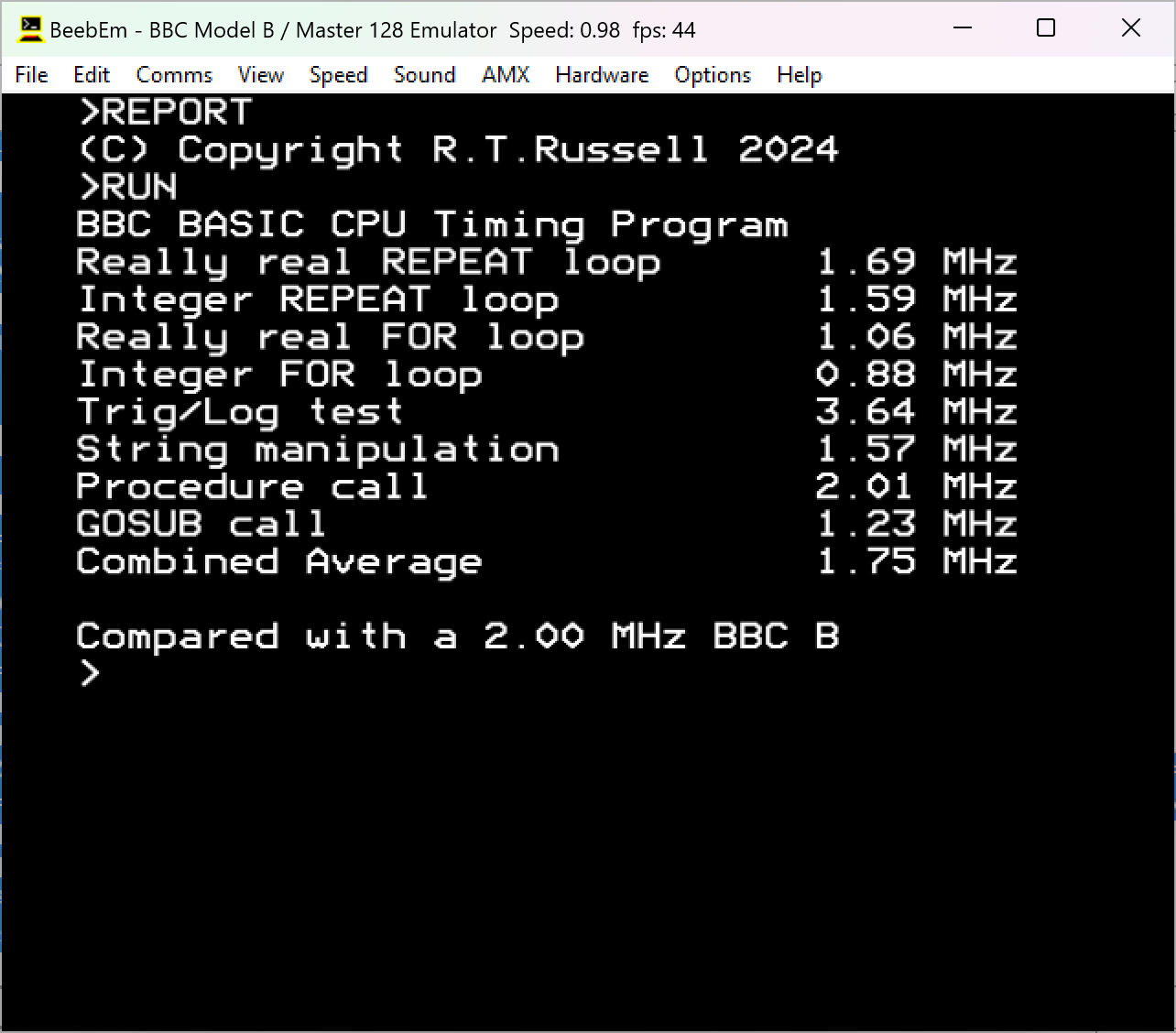
The SPEED.BBC results for version 2.20 and version 5.00 are shown below: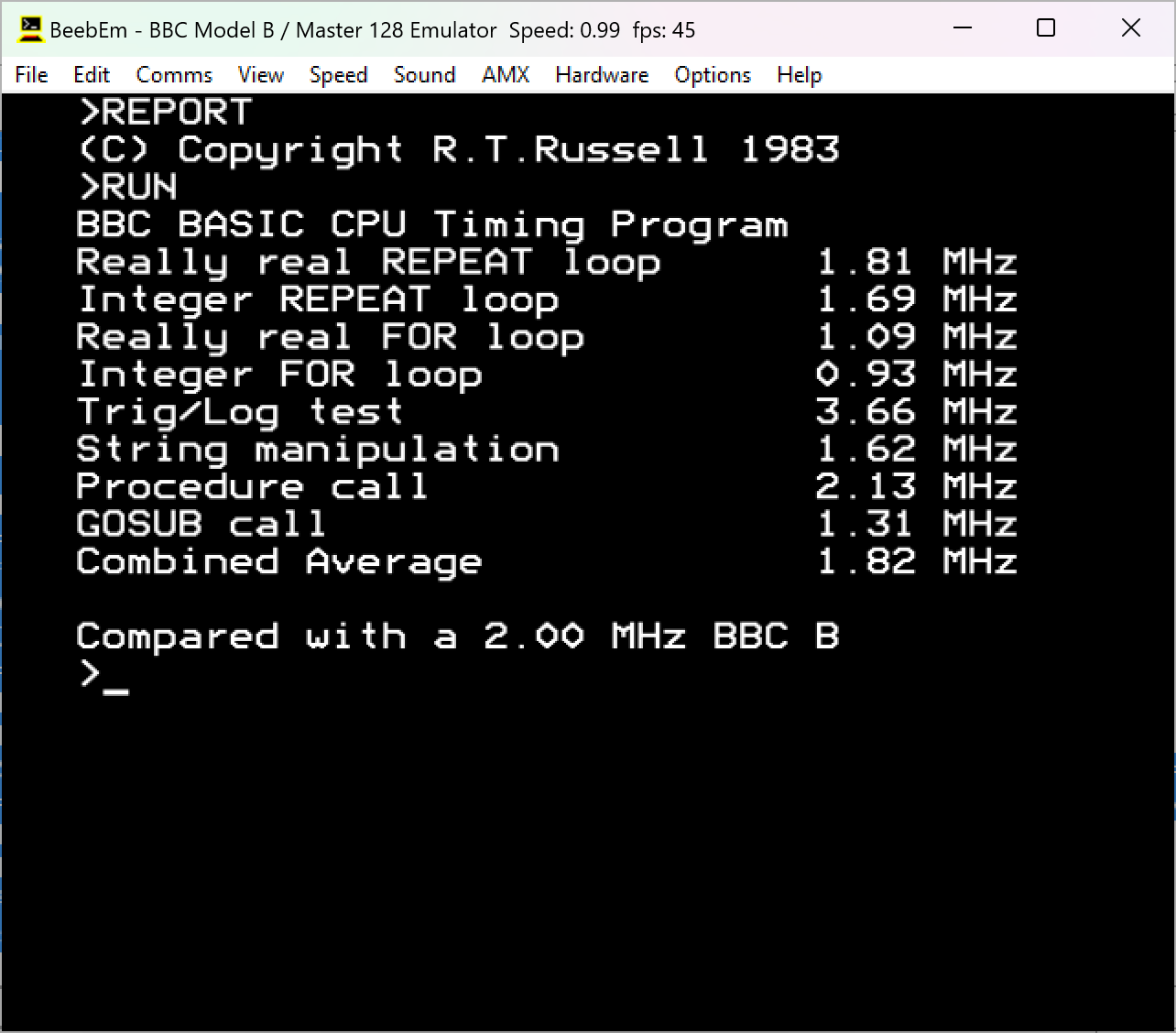
0 -
The Z80 Second Processor has a 6 MHz clock (Z80B), I think, so although I knew my interpreter was slow I didn't realise it was that slow, as measured by SPEED.BBC anyway (slower on a 6 MHz Z80 than Sophie's BASIC running on a 2 MHz 6502). That's terrible.Hated_moron wrote: »The SPEED.BBC results for version 2.20 and version 5.00 are shown below: 0
0 -
Bear in mind that the Z80 takes 4 T-states to perform each memory access. It isn't quite a 4:1 performance penalty, because it has more registers and a different (richer?) instruction set. But - in my opinion - one must discount the Z80's clock speed by some factor before making a comparison with 6502 - which makes a memory access in one cycle, of course. I think I've reckoned on 3x or 3.5x, but it depends very much on the code (and the coding style.) Perhaps see over here (6502 forum).0
-
Indeed, but I thought the accepted ratio was between about 2:1 and 2.5:1, so a 6 MHz Z80 ought to run between 20% and 50% faster than a 2 MHz 6502, whereas my BASIC is running more than 10% slower than Sophie's.one must discount the Z80's clock speed by some factor before making a comparison with 6502
0 -
I've done some more research on this, and the best 'real-world' ratio I can find is about 2.5, suggesting that my interpreter might be expected to run about 20% faster than Sophie's (it's actually a little more than 10% slower).Hated_moron wrote: »I thought the accepted ratio was between about 2:1 and 2.5:1
Those who quote a higher ratio (up to 3 or 4) tend to be comparing the execution time of similar instructions, without taking into account that the way you write code for the Z80 - with a relatively large register set - is very different from the way you write code for the 6502.
For example the 6502 typically uses zero-page memory as a kind of large register-bank, so it's doing a lot of memory accesses. If you wrote Z80 code to do a comparable number of memory accesses it would indeed probably need 4 times the number of clock cycles, but you don't. Where possible you use internal registers which can be accessed much more quickly.
This is confirmed by the breakdown of results from SPEED.BBC, which shows that the Z80 interpreter performs best when it's doing nearly everything in registers - such as the transcendental trig and log functions - and worse when it's forced to do lots of memory accesses - such as an integer FOR...NEXT loop.
It may well be that the nature of a BASIC interpreter is such that a greater number of memory accesses are involved than in more typical code, and that may be adversely affecting performance. I suppose the best comparison would be with other Z80 BASIC interpreters, but that could be a lot of work.
What I don't know is to what extent poor coding on my behalf is contributing to a slower speed. It's certainly true that I coded the interpreter for minimum size, not for maximum speed. Nowhere do I 'unroll loops' in the interest of making it faster but bigger.0 -
One other thing to consider, how cycle-accurate (if at all) is BeebEm's Z80 emulation? I'm not sure either about PiTubeDirect, certainly it runs much faster than a real Z80.0
-
Precisely so, as far as I'm aware (so long as 'Real time' is selected in the Speed menu). The 6502 emulation wouldn't work at all, with critical programs such as Elite, if it wasn't cycle-accurate so I would be surprised if the Z80 emulation was less accurate.One other thing to consider, how cycle-accurate (if at all) is BeebEm's Z80 emulation?
0
